负载均衡技巧
负载均衡算法
轮询&随机
基本原理
轮询:将请求依次发给服务器
随机:将请求随机发给服务器
适用场景
通用,无状态的负载均衡
优缺点
- 实现简单
- 不会判断服务器状态,除非服务器连接丢失
问题场景
- 某个服务器当前因为触发了bug进入死循环导致CPU负载很高,负载均衡系统是不感知的,还是会继续将请求源源不断发送给它
- 集群中新老服务器配置不一样,负载均衡系统也是不关注服务器性能差异,分配的任务都是一样
加权轮询
基本原理
按照预先配置,将请求按照权重比例发送给不同服务器
适用场景
服务器处理能力有差异,例如新老服务器搭配使用
优缺点
- 实现复杂,按照权重计算
- 不会判断服务器状态,除非服务器连接丢失
- 权限配置不合理导致过载(服务器处理能力并非按照硬件性能线性增长,很难估算配置)
问题场景
新服务器CPU核数是老服务器核数的2倍,运维直接配置了2倍权重,结果导致新服务器过载
算法
权重等于请求数量
例如给服务器1发送40个请求,然后再给服务器2发送40个请求,然后再给服务器3发送20个请求。
实现简单,但服务器资源利用可能不均匀,会出现毛刺现象。
权重概率
将所有服务器权重加起来,然后计算各个服务器的分配概率,用随机数区间来做分配。例如服务器1[0-39],服务器2[40-79],服务器3[80-99],生成0-99的随机数,落入哪个区就用哪个服务器。
权重动态调整
Ngnix的实现,兼顾服务器故障后的慢启动。
负载优先
基本原理
负载均衡系统将任务分配给当前负载最低的服务器,这里的负载根据不同的任务类型和业务场景,可以选用不同的指标来衡量。
适用场景
- LVS这种4层网络负载均衡设备,可以以“连接数”来判断服务器的状态,服务器连接数越大,说明服务器压力越大。
- Ngnix这种7层网络负载系统,可以以“HTTP请求数”来判断服务器状态(Nginx内置的负载均衡算法不支持这种方式,需要进行扩展)
优缺点
- 实现复杂,需要管理或者获取服务器状态
- 可以根据服务器状态进行负载均衡
性能优先
基本原理
负载均衡系统将任务分配给当前性能最好的服务器,主要是以响应时间作为衡量标准
适用场景
Ngnix这种7层网络负载系统,可以以“HTTP响应时间”来判断服务器状态(Nginx内置的负载均衡算法不支持这种方式,需要进行扩展)
优缺点
- 实现复杂,需要统计请求处理时间,需要消耗一定的CPU运算资源(一般通过采用方式统计)
- 可以根据服务器性能进行负载均衡
- 如果服务器响应不经过负载均衡器,则不能应用这种算法
Hash
基本原理
基于某个参数计算Hash值,将其映射到具体的服务器
适用场景
- 有状态的任务,如购物车
- 任务是分片的,例如某个用户请求只能在某个服务器处理
优缺点
- 实现简单
- 不会判断服务器状态,除非服务器连接丢失
常见Hash键
- URL(缓存场景)
- 用户IP地址(session场景)
业务级别负载均衡技巧
通用负载均衡算法是基于请求的,业务级别的负载均衡是基于业务内容的,
更灵活
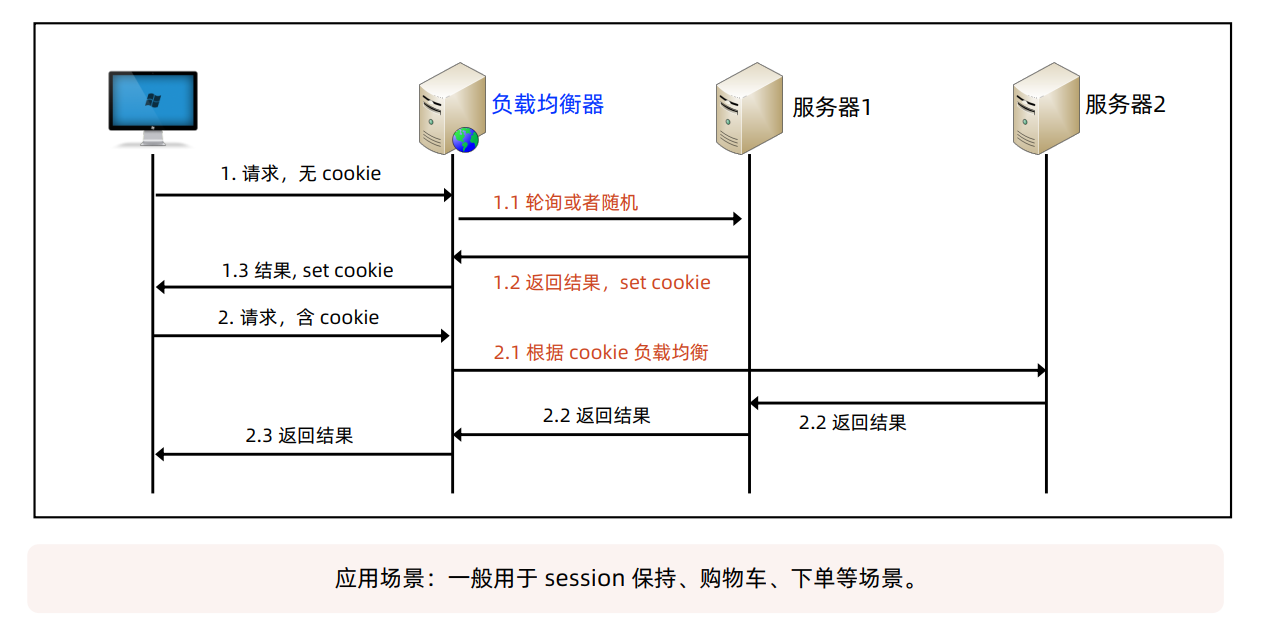
Cookie
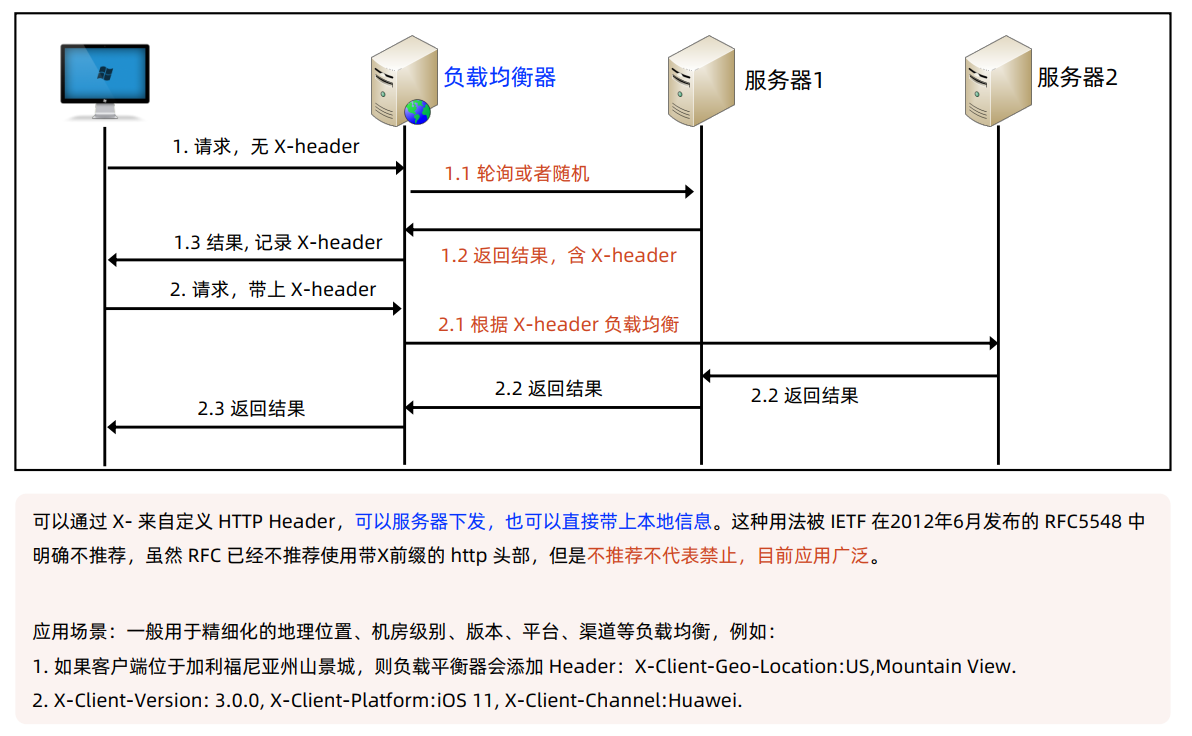
自定义HTTP Header
HTTP Query String

服务器性能估算

小结




