为什么 Kafka 不像 MySQL 那样允许追随者副本对外提供读服务
回答这个问题之前,我们先来看看Kafka的架构图
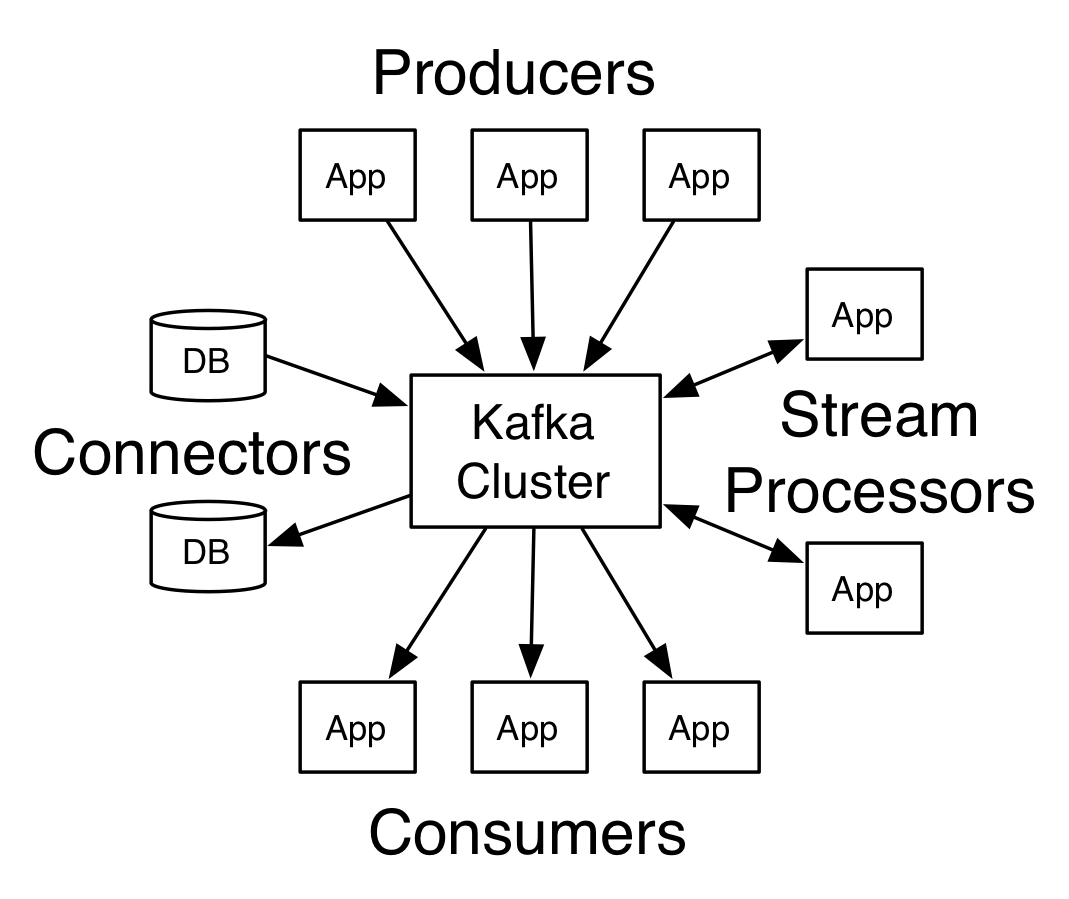
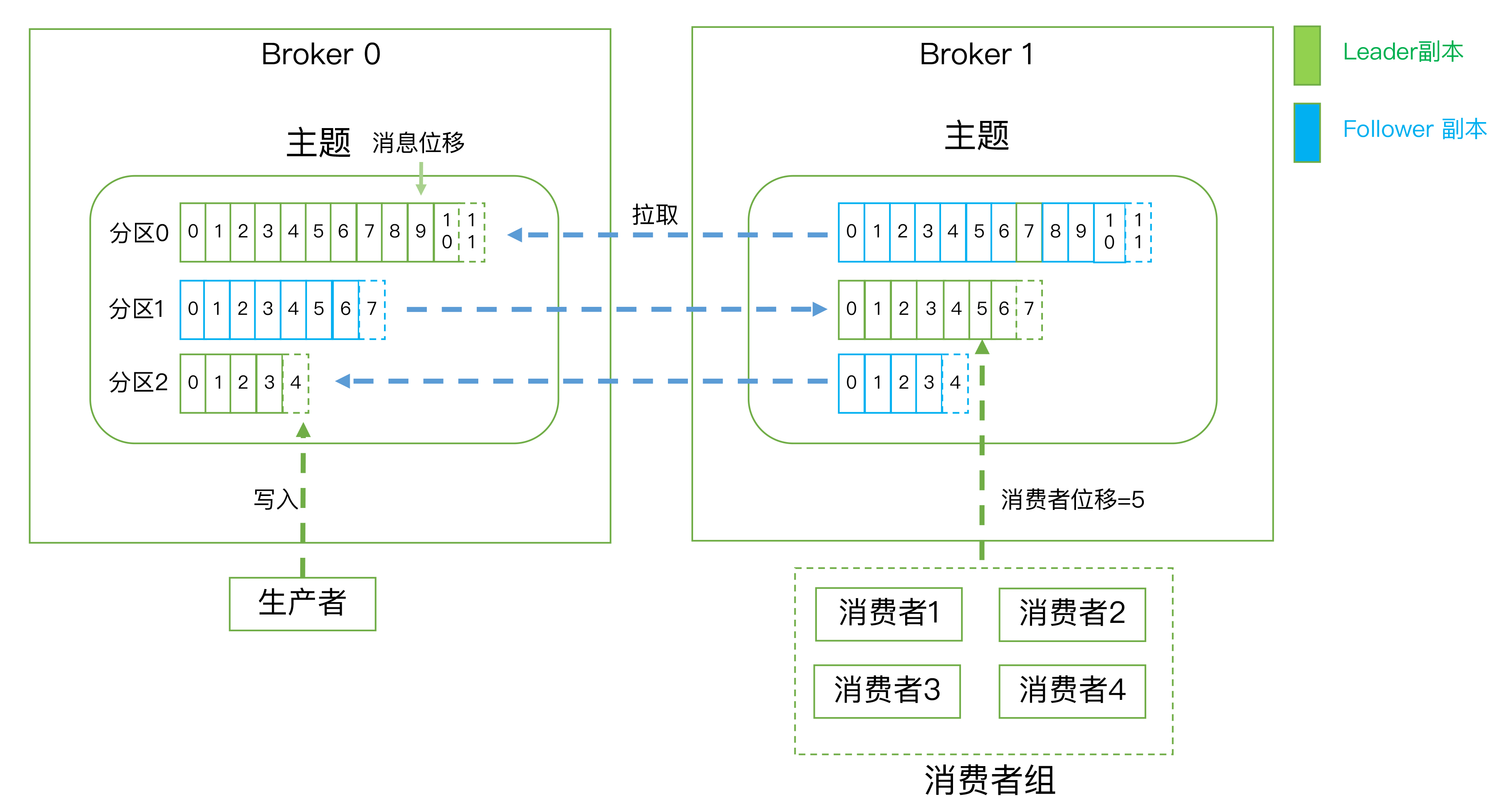
通常Kafka是以集群的方式运行,当然也可以单机,但是单机的Kafka一般只用来做实验、学习使用。从图中看到,Kafka包含了以下这些组成部分:
- Broker:Broker是Kafka的服务端,通常一个Kafka集群由多个Broker组成。Broker负责接收客户端的请求,消息持久化。多Broker保证了Kafka集群的高可用。
- Topic:主题是承载消息的逻辑容器。在实际中多用来区分具体的业务。
- Partition:一个有序不变的消息序列,一个主题可以有多个分区。
- Replica:副本提供消息冗余,是高可用的保障。一个分区可以有多个副本。副本分为领导者副本和追随者副本。领导者副本负责消息的读写,追随者副本只提供数据冗余。追随者副本会主动向领导者副本拉取消息进行同步。
- Producer:向主题发送消息的程序。生产者负责选择把记录分配到主题中的哪个分区。这可以使用轮询算法( round-robin)进行简单地平衡负载,也可以根据一些更复杂的语义分区算法(比如基于记录一些键值)来完成。
- Consumer:订阅主题消息的程序。
- Consumer Group:多个消费者实例共同组成一个组,同时消费多个分区的以实现高吞吐量。一个分区同时只能被一个消费者组中的一个消费者消费,而一个消费者可以消费多个分区。
- Record:消息,Kafka处理的主要对象。
- Offset:表示分区中每条消息的位置信息,一个单调递增且不变的值。
- Consumer Offset:消费者消费位移,表示消费进度,每个消费者都有自己的消费位移。
了解了Kafka的这些概念,我们再来回答开篇的问题。Kafka 不像 MySQL 那样允许追随者副本对外提供读服务主要有以下几个原因:
- MySQL副本提供读操作主要目的是分摊主库的压力,而Kafka每个主题可以是多分区的,数据已经均匀分散在各个分区上,而分区的领导者副本是在不同的Broker上,本身就已经把压力分摊了实现了负载均衡。
- 如果Kafka的追随者提供了读服务,因为领导者副本、追随者副本的同步时异步的,那么必然会造成数据的一致性问题。
- 如果Kafka的追随者提供了读服务,那么Broker的IO压力会增加,可能会降低集群的性能。



